
OPUS - an open source parallel corpus
OPUS is a growing collection of translated texts from the web. In the OPUS project we try to convert and align free online data, to add linguistic annotation, and to provide the data in various formats to make it easy to work with the data.
The main purpose is to support data-driven NLP especially statistical machine translation. Therefore, we provide various downloads of parallel data sets that can be used immediately for training standard MT models. Note, however, that we provide the data "as-is" without any warranties and guaranties. All pre-processing and alignment is done automatically and no manual corrections have been performed. Be aware of errors and noise. The quality of the data sets may also vary substantially.
Please, acknowledge our work by citing our papers and the source of the data. Do not hesitate to send us your feedback (and praise) and let us know how to improve our collection.
Information and Links
- Tools
- Data Formats
- Word Alignment
- Query Interfaces
- Word Alignment Database
- Information for NLPL Users
How to Download Data Sets
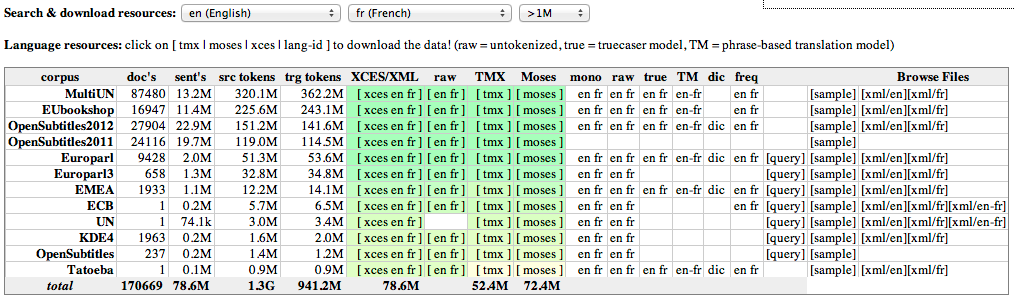
Data sets in OPUS can be downloaded in various formats. The easiest way to find resources is to use the form at the front page of OPUS. Select the languages you are interested in and look at the data sets provided in the table that shows the result of your query. Here is a recent screenshot that shows resources for English and French with more than 1 million parallel sentences (source and target language together):

Most table cells contain links to the appropriate resources. Click on them to download the data. Here is a brief description of information that you can find in this table:
- corpus: The name of the corpus is linked to a corpus-specific website where you can find more information and downloads
- XCES/XML: contains the tar-archives with the native XML format that OPUS uses to store all data.
- xces: sentence alignments as standoff annotation in XCES format
- language IDs: tar-files with tokenized standalone XML files for source and target language, respectively
- language IDs (raw): untokenized XML files for source and target language
- TMX: parallel data in the translation memory exchange format; these data files are collections of unique translation units
- Moses: parallel data in plain text format (Unicode UTF-8) without empty alignments in the format used by Moses (source and target texts in two separate files with corresponding lines being aligned to each other
- mono: tokenized monolingual plain text files with one sentence per line. This is useful for language modeling and may be (much) more than the parallel part of the corpus.
- raw: untokenized monolingual plain text files (in case you like to use your own tokenization)
- ud: parsed data in XML with dependency relations (using universal dependencies v 2.0), currently based on UDPipe with models from 2017-08-01
- alg: word alignment and phrase translation tables for phrase-based SMT created with efmaral and the Moses toolkit
- dic: a list of reliable alphabetic token links extracted from the automatic word alignment
- freq: a sorted frequency list of source and target language texts
Furthermore, there are sample files and query interfaces that you may look at for some corpora:
- query: this is a link to the search interface with parallel corpora indexed by the corpus work bench
- sample: a short sample file of the aligned data (which is not representative of the entire corpus)
- other files: other downloadable files depending on the resource, for example [alt] for the !OpenSubtitles2018 corpus that provides sentence alignments in XCES format for alternative movie subtitles; other possible files are intra-lingual alignments in different categories, which are also available for OpenSubtitles
Corpus-Specific Websites
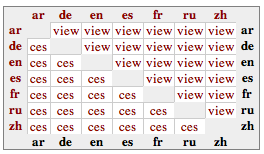
More information about each corpus in OPUS is collected on a corpus-specific website. Those pages usually have two tables with information and download links to individual bitexts. One table (alignment matrix) contains links to the native XML-formats we use for storing corpus data and sentence alignments. It looks like this:

Language IDs in the left-most column are linked to file archives with corpus files using a standalone XML format. The links on 'ces' point to the sentence alignments for corresponding languages in standoff annotation using the XCES alignment format. Links on 'view' point to small sample files for each bitext. The language IDs in the top row point to small sample files of tokenised XML data. Language IDs in the last row of the table may link to parsed corpora (if they exist).
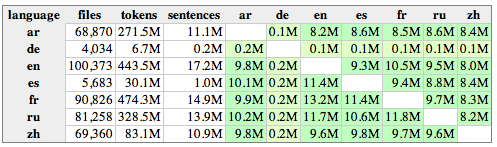
The second table includes statistics for each language and language pair and contains links to bitexts in plain text and TMX format. These tables look like this one:

The upper right triangle of the alignment matrix includes links to TMX files containing unique translation units and the lower left triangle includes links to plain text files in Moses format (one file per language with aligned sentences on corresponding lines). The numbers refer to approximate bitext sizes. Note that TMX files are usually smaller as they do not include duplicated sentence pairs.
Web API
We also run a web service for searching resources in OPUS. This is still a bit experimental but can be accessed from https://translate.ling.helsinki.fi/opusapi/ You can call it with url parameters corpus, source, target, preprocessing and version.
Here is an example: http://opus.nlpl.eu/opusapi/?corpus=Ubuntu&source=en&target=fi&preprocessing=xml&version=v14.10
The result of the query is returned in JSON and includes download links to the matching resources. Note that parallel texts require the monolingual resources that are linked to each other using the standoff annotation in the sentence alignment files. More information about the data formats is available from the wikipage on data formats.
Other Links
- Bookmarks (links and bookmarks with some relation to OPUS)
- Corpora (incomplete and outdated information)
- Web statistics using awstats
Internal Pages
Attachments (5)
- Screen Shot 2013-11-02 at 11.32.10 AM.png (116.4 KB) - added by joerg 7 years ago.
- Screen Shot 2013-11-02 at 1.25.15 PM.png (14.5 KB) - added by joerg 7 years ago.
- Screen Shot 2013-11-02 at 1.25.25 PM.png (30.0 KB) - added by joerg 7 years ago.
- select-resources.jpg (253.3 KB) - added by tiedeman 3 years ago.
- select-resources.png (234.6 KB) - added by tiedeman 3 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip